

































We present a training-free framework for continuous and controllable image editing at test time for text-conditioned generative models. In contrast to prior approaches that rely on additional training or manual user intervention, we find that a simple steering in the text-embedding space is sufficient to produce smooth edit control. Given a target concept (e.g., enhancing photorealism or changing facial expression), we use a large language model to automatically construct a small set of debiased contrastive prompt pairs, from which we compute a steering vector in the generator’s text-encoder space. We then add this vector directly to the input prompt representation to control generation along the desired semantic axis. To obtain a continuous control, we propose an elastic range search procedure that automatically identifies an effective interval of steering magnitudes, avoiding both under-steering (no-edit) and over-steering (changing other attributes). Adding the scaled versions of the same vector within this interval yields smooth and continuous edits. Since our method modifies only textual representations, it naturally generalizes across text-conditioned modalities, including image and video generation. To quantify the steering continuity, we introduce a new evaluation metric that measures the uniformity of semantic change across edit strengths. We compare the continuous editing behavior across methods and find that, despite its simplicity and lightweight design, our approach is comparable to training-based alternatives, outperforming other training-free methods.
Generate balanced positive and negative prompts, then keep only the concept-bearing token spans so the direction isolates the intended attribute.
A portrait of a frowning person in warm window light.
A portrait of a smiling person in warm window light.
A close-up shot of a frowning face beside a curtain.
A close-up shot of a smiling face beside a curtain.
A studio photo of a frowning figure wearing a blue shirt.
A studio photo of a smiling figure wearing a blue shirt.
Pool the selected token embeddings, average each side, take their difference, and normalize once to obtain the global steering direction ds.
Difference-of-means over pooled concept-token embeddings.
Implicit Prompt
Steer the main subject noun.
Explicit Prompt
Steer only the attribute token.
Implicit Prompt
Steer the main subject noun.
Explicit Prompt
Steer the style token.
Prompts are treated as implicit when the target attribute is absent, and explicit when it is already named.
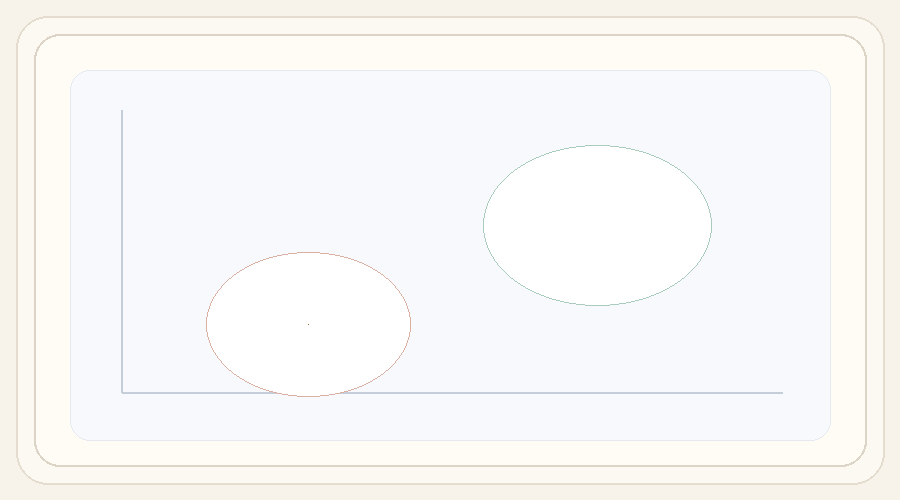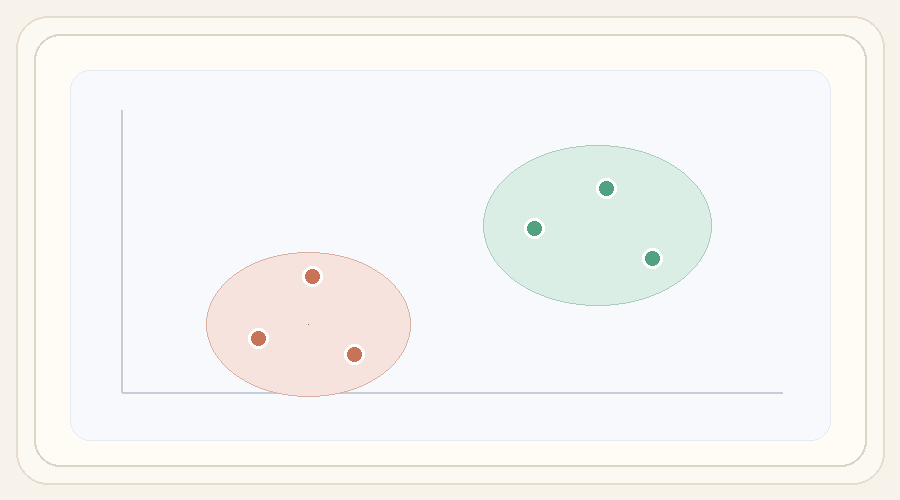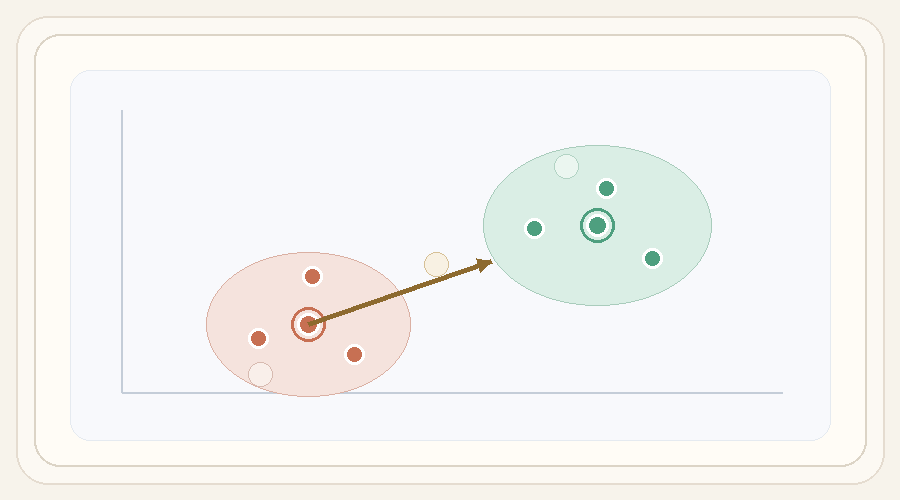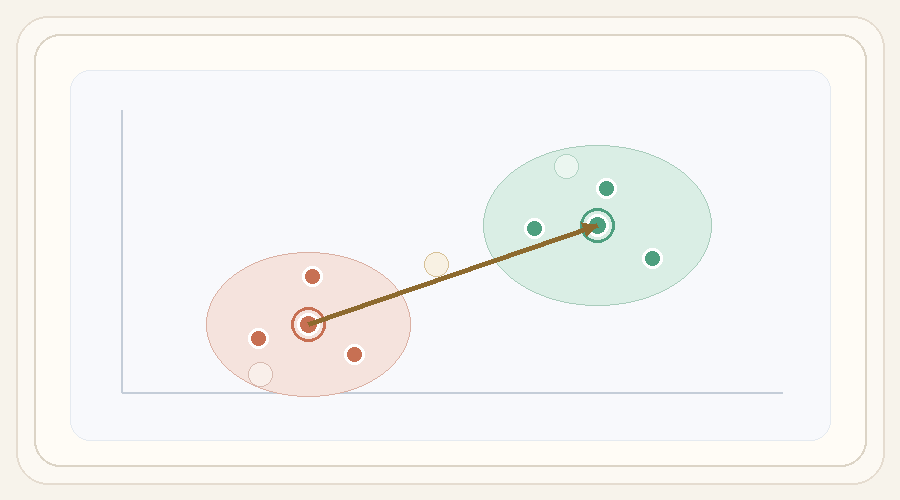
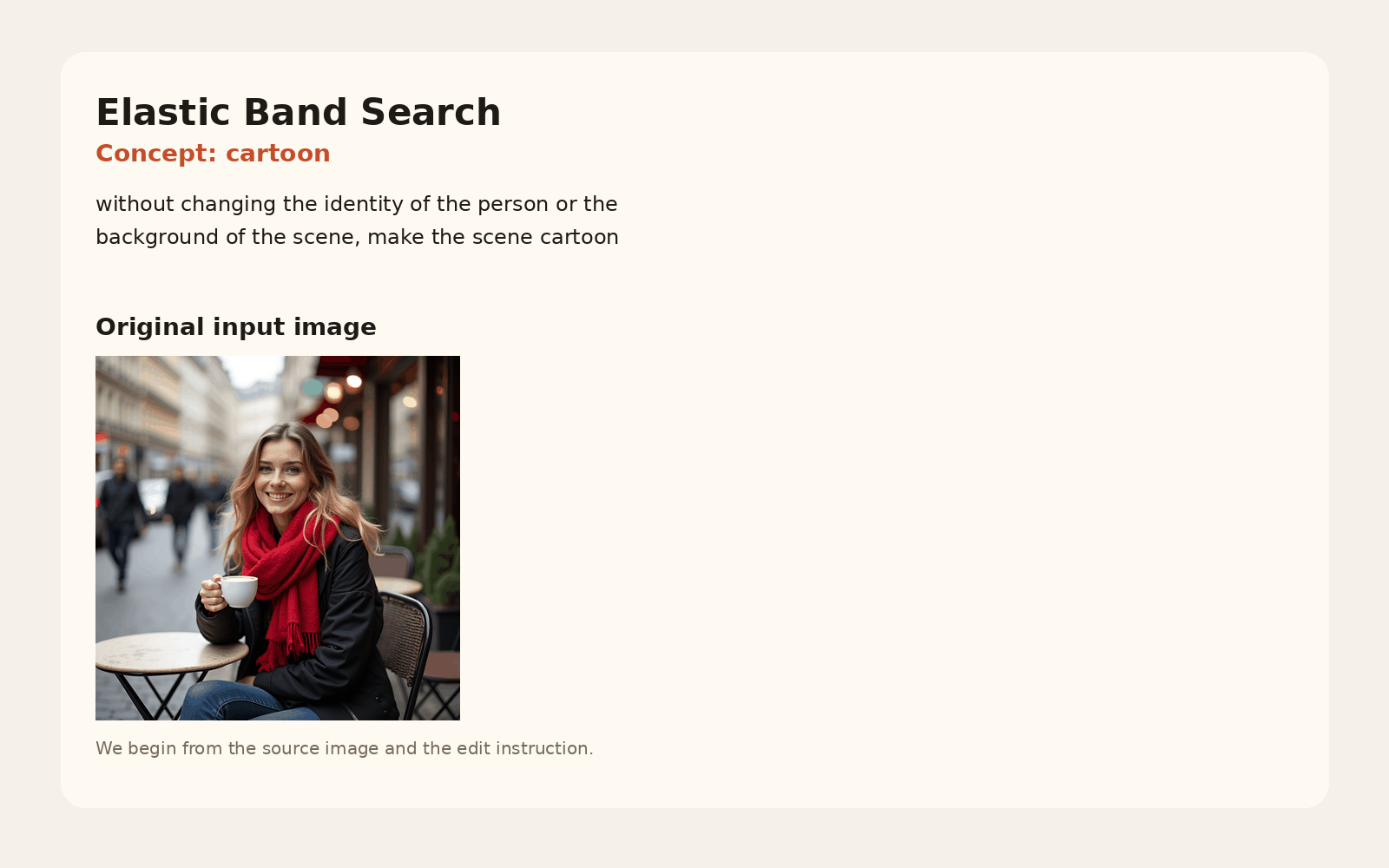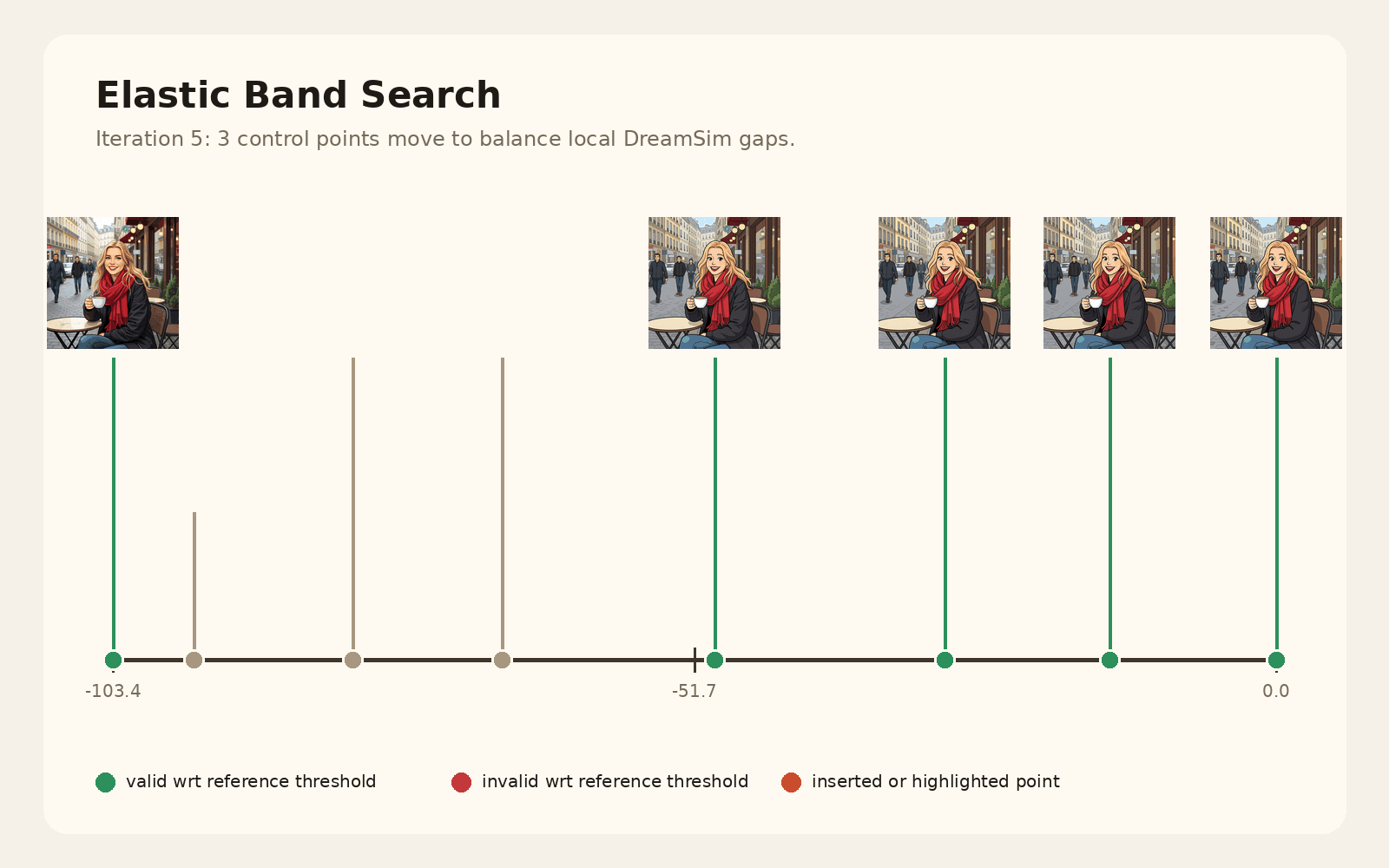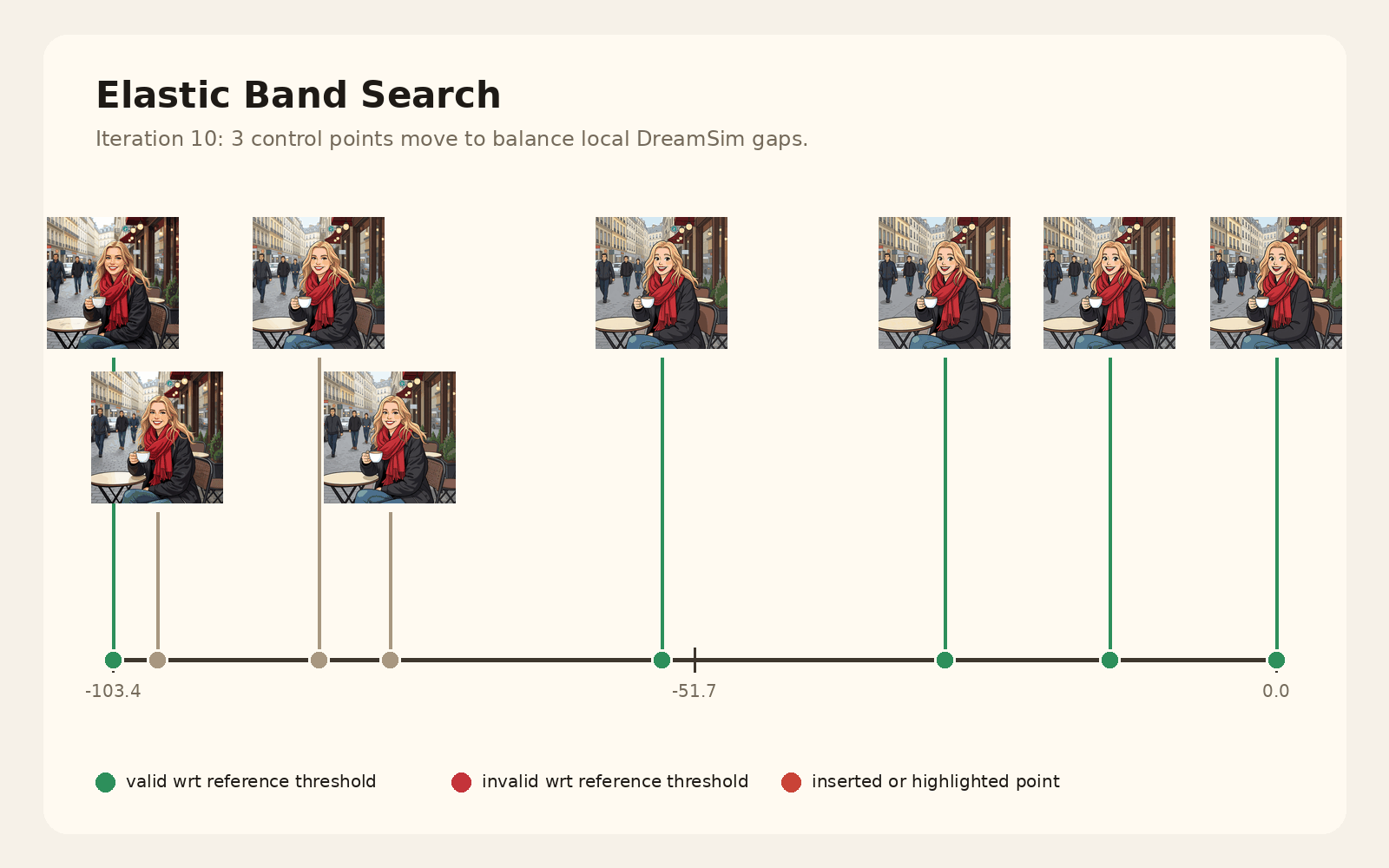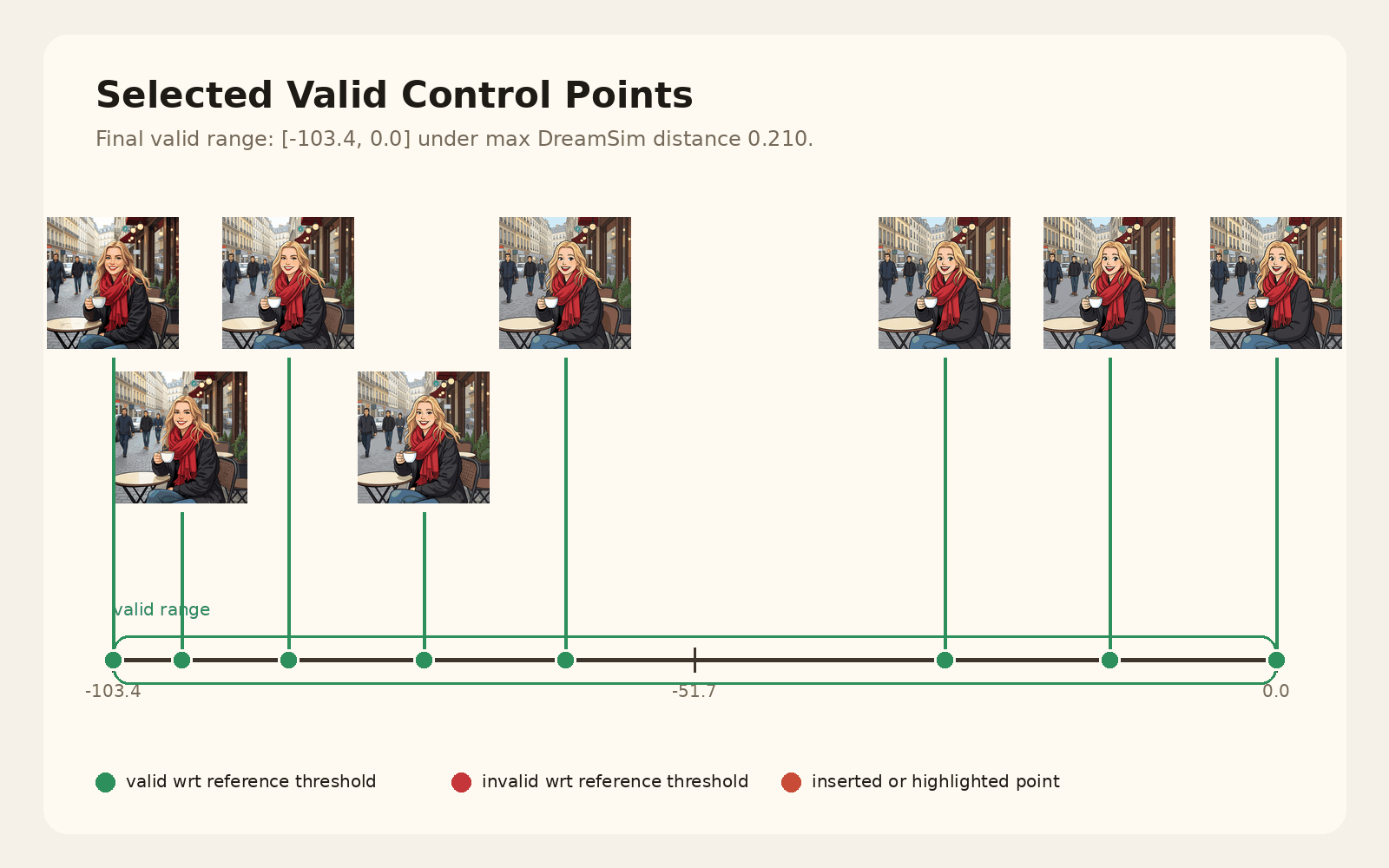
Given a steering direction, we need a usable range of strengths. We initialize a small set of anchor values, generate outputs for each one, and measure perceptual distances between neighboring edits.
The elastic band procedure then expands the range where gaps are too large, moves interior control points to equalize normalized gaps, and filters strengths that either change too little or distort the image too much relative to the unsteered anchor.
The toy animation below walks through the actual search loop: initialization, gap evaluation, midpoint expansion, left/right moves, and final similarity-based filtering into a usable slider range.
We show additional results on Qwen Image Edit and Flux2 models.
The image editing models below as well as the video models in the next section all rely on different text encoders, providing direct evidence that our method generalizes across different backbones.





















































Because we operate only on the text encoder, the same steering directions can also be applied to video backbones that share the same text encoder.
It is also possible to edit the first frame of a video and then use the VACE pipeline to propagate that edit consistently through the generated video.
@misc{ekin2026unreasonableeffectivenesstextembedding,
title={The Unreasonable Effectiveness of Text Embedding Interpolation for Continuous Image Steering},
author={Yigit Ekin and Yossi Gandelsman},
year={2026},
eprint={2603.17998},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2603.17998},
}