Results
We compare our object removal results with the state-of-the-art models below and show the results of our model on the COCO 2017 validation dataset.

Advanced image editing techniques, particularly inpainting, are essential for seamlessly removing unwanted elements while preserving visual integrity. Traditional GAN-based methods have achieved notable success, but recent advancements in diffusion models have produced superior results due to their training on large-scale datasets, enabling the generation of remarkably realistic inpainted images. Despite their strengths, diffusion models often struggle with object removal tasks without explicit guidance, leading to unintended hallucinations of the removed object.
To address this issue, we introduce CLIPAway, a novel approach leveraging CLIP embeddings to focus on background regions while excluding foreground elements. CLIPAway enhances inpainting accuracy and quality by identifying embeddings that prioritize the background, thus achieving seamless object removal. Unlike other methods that rely on specialized training datasets or costly manual annotations, CLIPAway provides a flexible, plug-and-play solution compatible with various diffusion-based inpainting techniques.
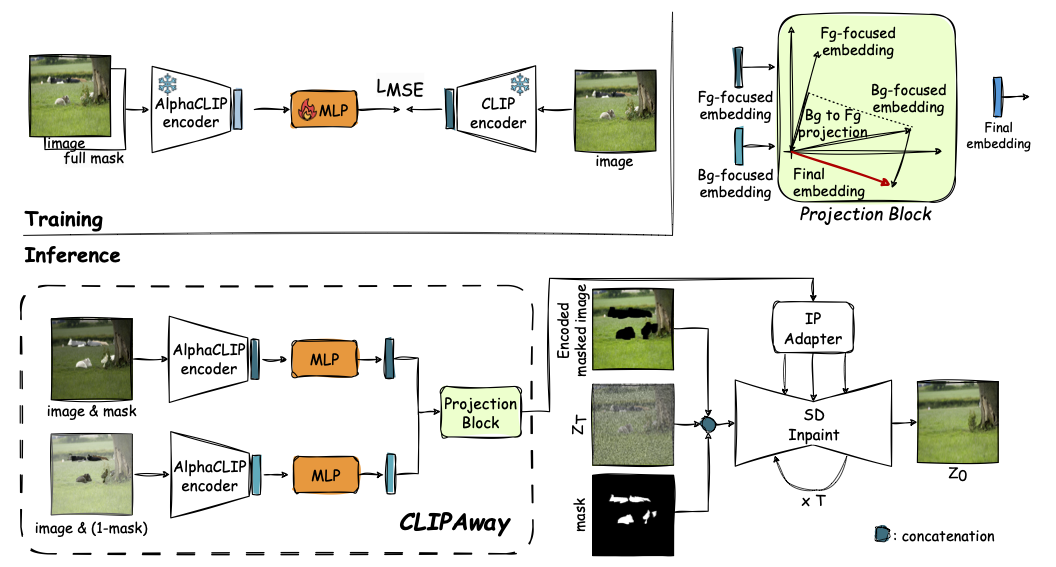
Training
aims to learn a mapping from AlphaCLIP's embedding space to IP-Adapter's embedding space.
This is achieved by training a MLP that maps the output of AlphaCLIP to the format expected by IP-Adapter. We give AlphaCLIP a full
mask (so that it focuses on the whole image) and the source image, project it using the mlp and apply MSE loss with the clip image embeddings of the same image for the specified clip image encoder of IP-Adapter.
Inference
is done by giving both pairs of source image and mask and source image and 1-mask to AlphaCLIP and projecting the embeddings to the IP-Adapter's embedding space using the trained MLP.
Then, we give the projected embeddings to the projection block to remove the object from the embeddings. This is done by subtracting the background-focused embeddings projection of foreground-focused embeddings from itself.
Finally, we give the modified embeddings to the IP-Adapter's generator to get the inpainted image.
We compare our object removal results with the state-of-the-art inpainting method SD-Inpaint

We compare our object removal results with the state-of-the-art models below and show the results of our model on the COCO 2017 validation dataset.
We display the effect of our projection block by displaying unconditional image generation for foreground-focused, background-focused and projected embeddings

Our work has been inspired by many recent works in the field. Here are some of the most relevant ones:
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
@inproceedings{NEURIPS2024_1f6f0b6e,
author = {Ekin, Yi\u{g}it and Yildirim, Ahmet Burak and Caglar, Erdem Eren and Erdem, Aykut and Erdem, Erkut and Dundar, Aysegul},
booktitle = {Advances in Neural Information Processing Systems},
editor = {A. Globerson and L. Mackey and D. Belgrave and A. Fan and U. Paquet and J. Tomczak and C. Zhang},
pages = {17572--17601},
publisher = {Curran Associates, Inc.},
title = {CLIPAway: Harmonizing focused embeddings for removing objects via diffusion models},
url = {https://proceedings.neurips.cc/paper_files/paper/2024/file/1f6f0b6eec8a4ff0f6baa707ff91a442-Paper-Conference.pdf},
volume = {37},
year = {2024}
}